Vad är generativ AI?
Låt oss börja med lite teori. Lita på mig, du kommer att ha glädje av det senare i kursen. Så, vad är generativ AI egentligen? Generativ AI är ett övergripande begrepp som syftar till en typ av artificiell intelligens som kan skapa nytt innehåll, som text, bilder, musik och mycket mer.
Vanligtvis fokuserar en generativ AI-modell på att bara producera en sorts innehåll, exempelvis text eller bilder. En AI-modell som kan producera i flera olika sorters medier kallas för multimodal AI.Sedan hösten 2025 har fullständigt multimodal förmåga blivit mer av en standard än ett undantag bland de ledande AI-tjänsterna. De hanterar nu text, bilder, ljud och kod i en och samma modell, utan att du behöver byta till en separat tjänst för varje innehållstyp.
Den mest kända sorten av generativ AI som vi huvudsakligen fokuserar på i den här kursen är stora språkmodeller (på engelska LLM – Large language models) som är designade för att förstå och generera mänskligt språk. Något som är bra att ha med sig genom det här avsnittet är att tänka på att när en stor språkmodell genererar text, så gör den det hela tiden ett ord i taget baserat på vad som är det mest sannolika nästa ordet i en mening.
Detta fungerar ungefär enligt samma princip som ordprediktionen i din telefon när du ska skriva ett sms, som föreslår nästa ord i meningen, eller ordprediktionen när du använder till exempel Google, som föreslår nästa ord i din söksträng. Men, hur funkar egentligen den tekniken, och hur kan en så till synes enkel teknik göra att någonting så komplext som en stor språkmodell fungerar?

Maskininlärning är hur AI lär sig
Till skillnad från traditionell programvara som följer fasta regler (exempelvis Microsoft Word där en programmerare har programmerat exakt vad som händer när du klickar på olika funktioner i ett worddokument), utvecklar generativa AI-modeller förståelse för underliggande strukturer i information och kan sedan producera originalverk baserat på de mönster och data den har lärt sig. Ett begrepp du kanske har hört förut är maskininlärning (eller machine learning på engelska), och det kan vara bra att placera det rätt i sammanhanget. Maskininlärning är ett samlingsnamn för tekniker där datorer tränas att hitta mönster i data utan att vara uttryckligen programmerade för varje uppgift.
När vi säger att en språkmodell “tränas” på stora mängder text, är det alltså genom maskininlärning. Men hur går träningen till mer specifikt för att modellen ska lära sig språkets mönster? Det görs genom en process som ofta kallas självövervakad träning. Modellen matas med enorma mängder text: böcker, artiklar, webbsidor, och istället för att få uppgifter att utföra med färdiga ’rätta svar’ presenteras den för en uppgift som den själv kan lära sig ifrån: exempelvis att förutsäga nästa ord i en sekvens.
Tänk dig att modellen får se meningen “Jag vill äta en …” Dess uppgift är då att “gissa” vilket ord som mest sannolikt kommer härnäst, till exempel “äpple”, “pizza” eller ”macka”. Modellen jämför sin gissning med det faktiska nästa ordet i den text den tränas på. Om den “gissar” fel, justeras dess inre parametrar så att den lär sig av sitt misstag och blir bättre på liknande situationer i framtiden. Genom att upprepa denna process miljarder gånger på otaliga meningar lär sig modellen att identifiera komplexa grammatiska strukturer, semantiska samband och typiska fraser i språket. Det är just denna ständiga övning i att förutsäga nästa ord som bygger upp modellens djupa förståelse för språkets mönster. Genom detta lär sig modellen inte bara språkets form utan också dess typiska innehåll och variationer.
En annan viktig detalj är att träningsdatan som modellen tränas på inte matas in som rena ord eller meningar. Istället delas allt upp i mindre byggstenar som kallas tokens. En token kan vara ett ord, delar av ord eller till och med enskilda tecken beroende på språk och sammanhang. Det är med hjälp av dessa tokens som modellen lär sig sina statistiska mönster. Olika språkmodeller klarar av att hantera olika stora mängder tokens. Den här mängden tokens begränsar hur mycket information en språkmodell kan hålla i sitt arbetsminne för tillfället. Exempelvis hur stora mängder text du kan mata in i en prompt eller hur lång en konversation kan bli innan modellen börjar glömma bort information. Hur stora mängder tokens en modell klarar av att hantera har utvecklats mycket de senaste åren. När ChatGPT 3.5 släpptes 2022 klarade den av att hantera cirka 4 000 tokens.
År 2025 hade den siffran utökats till cirka 400 000 tokens. Nu i mars 2026 ligger rekordet för de främsta publika modellerna på 2 miljoner tokens.
För att sätta den siffran i ett sammanhang innebär det att du i en enda prompt kan skicka med:
- Över 1,5 miljoner ord
- Cirka 22 timmar ljud
- Över 2 timmar video
- Omkring 60 000 rader kod
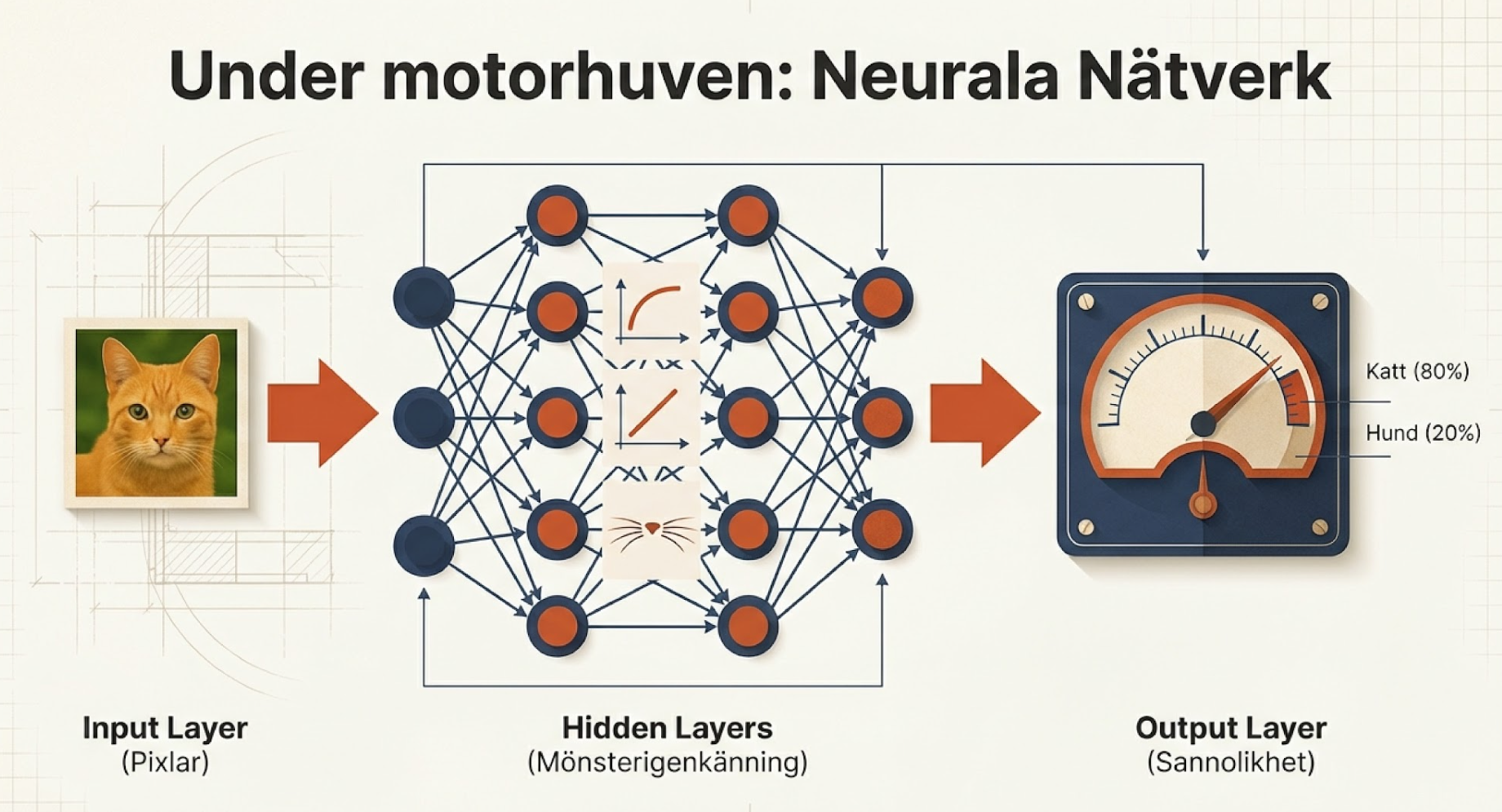
Neurala nätverk är tekniken under motorhuven
Stora språkmodeller är ett exempel på AI som bygger på sådan här maskininlärning, men principen som jag förklarade precis innan är lite av en simplifiering. När dessa modeller tränas används den teknik som kallas djupinlärning (deep learning), där man använder något som kallas djupa neurala nätverk med många lager. Kort och gott så säger vi bara ”neurala nätverk” från och med nu.
Neurala nätverk utgör ryggraden i alla moderna generativa AI-system. Dessa datorsystem har faktiskt funnits sedan 1957 och är inspirerade av hur den mänskliga hjärnan bearbetar information genom sammankopplade neuroner. I praktiken består ett neuralt nätverk av ett stort nätverk bestående av noder där varje nod motsvarar en av hjärnans neuroner. Noderna i sin tur är indelade i flera lager där varje lager omvandlar och förfinar informationen stegvis från rådata till meningsfull utdata.

Detalj ur Digital Nomads Beyond the Cubicle av Yutong Liu & Digit tagen från Better Images of AI Licens: Creative Commons Erkännande 4.0 Internationell (CC BY 4.0) //Beskuren
Arkitekturen inkluderar typiskt ett indatalager som tar emot rådata (träningsdatan i form av stora mängder text), dolda lager som identifierar mönster och kombinerar funktioner (flera lager med maskininlärning), samt ett utdatalager som producerar det slutliga resultatet (färdiga mönster och strukturer som den stora språkmodellen sen kan använda för att generera text).
Verkar det krångligt? Vi kan illustrera med ett enkelt exempel. Föreställ dig ett neutralt nätverk som har fyra lager med noder. Ett riktigt neutralt nätverk har betydligt fler lager och noder men för enkelhetens skull så tänker vi oss ett litet nätverk. Du vill använda det här neurala nätverket för att identifiera bilder på katter. Du matar in en massa bilder på katter, hundar och människor. De här bilderna hamnar i första lagret (input layer) och blir till rådata i form av pixlar.
Nästa lager av noder (hidden layers) kommer att börja undersöka den här rådatan. De kanske noterar att olika bilder har pixelsammansättningar som en människa skulle tolka som olika färgskiftningar och mönster. Sen skickar noderna vidare datan till nästa lager som i sin tur undersöker datan efter andra mönster. Kanske ifall färgskiftningarna bildar vissa mönster som en människa skulle känna igen som ett morrhår, men som för språkmodellen bara är en ansamling av mer strukturerade pixlar.
Till sist skickar noderna den här informationen vidare till det sista lagret (output layer) där systemet gör en gissning ifall bilden som matades in i första lagret föreställer en katt eller inte. Svaret är inte entydigt ja eller nej utan snarare 80 % katt och 20 % hund. Men när vi får svaret så kommer nätverket att översätta detta till att sannolikheten för att bilden föreställer en katt är hög. Baserat på de här gissningarna så kommer nätverket att ha lärt sig vissa mönster för sannolikheten att en bild föreställer en katt eller inte.
Något som är viktigt att påpeka här är att ingen programmerare har gått in och sagt åt de olika lagren eller noderna vilken typ av mönster de ska leta efter, det avgör de själva. Därför vet man inte alltid vad ett nätverk reagerar på i rådatan. Ett känt exempel är ett sjukhus som tränade ett nätverk att upptäcka hjärntumörer, men modellen började bara känna igen sjukhusets logga i bildhörnet eftersom den råkade finnas på alla träningsbilder med tumörer.

Detalj ur Digital Nomads Beyond the Cubicle av Yutong Liu & Digit tagen från Better Images of AI Licens: Creative Commons Erkännande 4.0 Internationell (CC BY 4.0) //Beskuren
Om man ska översätta den här beskrivningen till hur en stor språkmodell fungerar så kan man säga lite förenklat att språkmodellen har lärt sig att känna igen mönster i mänskligt språk genom att studera tillräckligt stora mängder av det för att kunna se statistiska samband. Utifrån de här statistiska sambanden kan den beräkna det mest troliga nästa ordet i en mening och på så vis bygga en text, ord för ord, som är fullt begriplig för människor. Men det är värt att nämna att språkmodellen inte alltid väljer det mest troliga ordet. Det finns en inställning som kallas för “temperatur” som inför en kaosfaktor i hur stor hänsyn till sannolikheten modellen ska ta när den väljer nästa ord. Den här temperaturen kan vara lågt inställd, och då blir variationen liten, eller högt inställd, och då blir variationen stor.
Så kort sagt: generativ AI är ett tillämpningsområde, neurala nätverk är tekniken under huven, och maskininlärning är själva träningsmetoden som gör att allt fungerar.

Detalj ur Digital Nomads Beyond the Cubicle av Yutong Liu & Digit tagen från Better Images of AI Licens: Creative Commons Erkännande 4.0 Internationell (CC BY 4.0) //Beskuren
Transformers är superkraften som gör allt möjligt
Medan maskininlärning och neurala nätverk utgör den bredare grunden är det en specifik arkitektur kallad transformerarkitektur, så kallade transformers, som verkligen har drivit fram de senaste årens genombrott inom stora språkmodeller som ChatGPT.
Transformers introducerades 2017 och förändrade spelplanen för hur maskiner kan bearbeta språk. Istället för att läsa text i ordning, ett ord i taget som tidigare modeller ofta gjorde, kan en transformermodell titta på hela texten samtidigt och väga varje ords betydelse i relation till de andra. Det här kallas self attention och det gör att modellen kan förstå att till exempel ordet ”bank” betyder något helt annat i meningen ”han satt vid flodens bank” än i ”hon gick till banken för att ta ut pengar”. Med self attention kan modellen koppla samman rätt saker i en kontext, vilket är en avgörande funktion för att det ska bli begripligt och relevant. Det är den här tekniken som exempelvis gör att du kan ha en lång konversation med generativ AI, och den kommer att kunna komma ihåg vad du har sagt eller skrivit tidigare i konversationen.
Minns du hur vi ovan gick igenom att tokens är ett sätt att bryta ner språket, som gör att en stor språkmodell klarar av att förstå vad ett ord betyder och hålla mycket information i sitt arbetsminne? Tekniken bakom tokens har funnits mycket längre än transformers, men när de två teknikerna kombinerades blev stora språkmodeller möjliga. Tokens var själva byggstenen, men det var transformerarkitekturens förmåga att med self attention analysera alla dessa tokens parallellt som verkligen revolutionerade språkförståelsen.
Allt detta, maskininlärning, tokenisering, neurala nätverk, transformers, attentionmekanismer, gör att stora språkmodeller kan efterlikna mänskligt språk på ett sätt som faktiskt känns naturligt och ibland till och med överraskande smart.